Best Matching 25 (BM25) ist ein Ranking-Algorithmus, der verwendet wird, um Dokumente nach ihrer Relevanz für eine Suchanfrage zu bewerten. BM25 gehört zur Familie der „Bag of Words“-Modelle, die den Text als Sammlung von Wörtern ohne Berücksichtigung ihrer Reihenfolge betrachten. Er ist ursprünglich nach dem ersten System benannt, indem er genutzt wurde: dem Okapi information retrieval system der London City University.
Wie funktioniert BM25?
BM25 basiert auf der Wahrscheinlichkeitstheorie und ist ein TF-IDF Algorithmus. Er beruht dementsprechend auf zwei Hauptfaktoren:- Term Frequency (TF): Wie oft ein Suchbegriff (Term) im Dokument vorkommt.
- Inverse Document Frequency (IDF): Wie selten ein Suchbegriff in der gesamten Dokumentensammlung vorkommt.
Mathematische Darstellung:
Die BM25+ Bewertung eines Dokuments D für eine Suchanfrage Q wird folgendermaßen berechnet:
\( BM25_+(D,Q) = \sum_{i=1}^{n} IDF(q_i) \cdot \left[ \frac{f \left( q_i,D \right) \cdot \left( k_1 + 1 \right)}{f \left( q_i,D \right) + k_1 \cdot \left( 1-b+b \cdot \frac{|D|}{avgdl} \right) } + \delta \right]
\)
Hierbei gilt:
- \(q_i\): Der i-te Begriff in der Suchanfrage.
- \(f \left( q_i,D\right) \): Die Häufigkeit von \(q_i\) in Dokument D.
- |D|: Die Länge des Dokuments (Anzahl der Wörter).
- avgdl: Die durchschnittliche Dokumentlänge in der Sammlung.
- \(k_1\) und b: Hyperparameter. Üblicherweise wird \(k_1\) auf einen Wert zwischen 1.2 und 2.0 gesetzt und b auf etwa 0.75.
- \(\delta\): Zusätzlicher freier Parameter im Vergleich zum Standard-BM25. Der typische Wert ist 1.0 in Abwesenheit von Trainingsdaten [R1].
Berechnung von IDF
Die IDF-Komponente ist bei BM25+ definiert als [R3]:
\( IDF(q_i) = \log \left( \frac{N+1}{n(q_i)} \right)
\)
- N: Die Gesamtzahl der Dokumente.
- \(n(q_i)\): Die Anzahl der Dokumente, die den Begriff \(q_i\) enthalten.
Beispiel
Nehmen wir an, wir haben eine kleine Sammlung von Dokumenten und eine Suchanfrage. Unsere Dokumentensammlung besteht aus den folgenden drei bekannten Dokumenten (Sätzen):
- Doc1: „Ich liebe Pizza.“
- Doc2: „Heute mache ich mir eine Pizza.“
- Doc3: „Gestern habe ich Pasta gegessen.“
Unsere Suchanfrage lautet: „Heute Pizza“.
Schritt 1: Berechnung von IDF
Zuerst berechnen wir die IDF-Werte für die Begriffe „Heute“ und „Pizza“.
- IDF(„Heute“): Der Begriff „Heute“ kommt in 1 von 3 Dokumenten vor.
\( IDF_{Heute} = \log \left( \frac{3+1}{1} \right) \approx 1.39 \) - IDF(„Pizza“): Der Begriff „Pizza“ kommt in 2 von 3 Dokumenten vor.
\( IDF_{Pizza} = \log \left( \frac{3+1}{2} \right) \approx 0.69 \)
Schritt 2: Berechnung der BM25+ Scores
Nun berechnen wir die BM25+ Scores für jedes Dokument:
- Doc1: „Ich liebe Pizza.“
Der Begriff „Heute“ kommt in Doc1 nicht vor:
\( f(„Heute“, Doc1) = 0 \)
\( BM25_+(Doc1, „Heute“) = 1.39 \cdot \left[ \frac{0 \cdot \left( 1.5 + 1 \right)}{0 + 1.5 \cdot \left( 1 – 0.75 + 0.75 \cdot \frac{3}{4.67} \right) } + 1 \right] \approx 1.39 \)
Der Begriff „Pizza“ kommt 1x in Doc1 vor:
\( f(„Pizza“, Doc1) = 1 \)
\( BM25_+(Doc1, „Pizza“) = 0.69 \cdot \left[ \frac{1 \cdot \left( 1.5 + 1 \right)}{1 + 1.5 \cdot \left( 1 – 0.75 + 0.75 \cdot \frac{3}{4.67} \right) } + 1 \right] \approx 1.52 \)
Gesamtscore für Doc1:
\( BM25_+(Doc1, „Heute \, Pizza“) \approx 1.39 + 1.52 = 2.91 \) - Doc2: „Heute mache ich mir eine Pizza.“
Der Begriff „Heute“ kommt in Doc2 1x vor:
\( f(„Heute“, Doc2) = 1 \)
\( BM25_+(Doc2, „Heute“) = 1.39 \cdot \left[ \frac{1 \cdot \left( 1.5 + 1 \right)}{1 + 1.5 \cdot \left( 1 – 0.75 + 0.75 \cdot \frac{6}{4.67} \right) } + 1 \right] \approx 2.61 \)
Der Begriff „Pizza“ kommt 1x in Doc2 vor:
\( f(„Pizza“, Doc2) = 1 \)
\( BM25_+(Doc2, „Pizza“) = 0.69 \cdot \left[ \frac{1 \cdot \left( 1.5 + 1 \right)}{1 + 1.5 \cdot \left( 1 – 0.75 + 0.75 \cdot \frac{6}{4.67} \right) } + 1 \right] \approx 1.31 \)
Gesamtscore für Doc2:
\( BM25_+(Doc2, „Heute \, Pizza“) \approx 2.61 + 1.31 = 3.92 \) - Doc3: „Gestern habe ich Pasta gegessen.“
Der Begriff „Heute“ kommt in Doc3 nicht vor:
\( f(„Heute“, Doc3) = 0 \)
\( BM25_+(Doc3, „Heute“) = 1.39 \cdot \left[ \frac{0 \cdot \left( 1.5 + 1 \right)}{0 + 1.5 \cdot \left( 1 – 0.75 + 0.75 \cdot \frac{5}{4.67} \right) } + 1 \right] \approx 1.39 \)
Der Begriff „Pizza“ kommt in Doc3 nicht vor:
\( f(„Pizza“, Doc3) = 0 \)
\( BM25_+(Doc3, „Pizza“) = 0.69 \cdot \left[ \frac{0 \cdot \left( 1.5 + 1 \right)}{0 + 1.5 \cdot \left( 1 – 0.75 + 0.75 \cdot \frac{5}{4.67} \right) } + 1 \right] \approx 0.69 \)
Gesamtscore für Doc3:
\( BM25_+(Doc3, „Heute \, Pizza“) \approx 1.39 + 0.69 = 2.08 \)
Zusammenfassung der Scores
Die Dokumente werden basierend auf ihrem BM25+ Score für die Suchanfrage „Heute Pizza“ wie folgt gerankt:
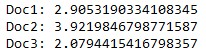
- Doc2: 3.92 („Heute mache ich mir eine Pizza.“)
- Doc1: 2.91 („Ich liebe Pizza.“)
- Doc3: 2.08 („Gestern habe ich Pasta gegessen.“)
Zusammenfassung
BM25(+) bietet eine ausgezeichnete Möglichkeit, die Grundlagen der Textsuche und Relevanzbewertung zu verstehen. Die Metrik zeigt, wie einfache mathematische Konzepte wie Term Frequency und Inverse Document Frequency kombiniert werden können, um praktische und effektive Lösungen zu entwickeln. BM25(+) dient dabei als solides Fundament, auf dem weitere, komplexere Modelle und Algorithmen aufgebaut werden können.
Implementierung in Python
Die Python-Bibliothek rank_bm25 bietet eine einfache Möglichkeit, BM25+ in Python zu nutzen. Dazu wollen wir das oben berechnete Beispiel testen:
# Importiere Pakete
from rank_bm25 import BM25Plus
# Dokumentensammlung
documents = [
„Ich liebe Pizza“,
„Heute mache ich mir eine Pizza“,
„Gestern habe ich Pasta gegessen“
]
# Tokenisierung der Dokumente
tokenized_documents = [doc.split(“ „) for doc in documents]
# Initialisierung des BM25+ Modells
bm25 = BM25Plus(tokenized_documents)
# Suchanfrage
query = „Heute Pizza“
tokenized_query = query.split(“ „)
# Berechnung der Scores
scores = bm25.get_scores(tokenized_query)
# Ausgabe der Scores
for i, score in enumerate(scores):
print(f“Doc{i+1}: {score}“)
# Ausgabe der IDF-Werte
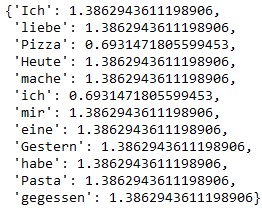
bm25.idf
Dieser Code zeigt, wie BM25+ verwendet werden kann, um die Relevanz von Dokumenten für eine gegebene Suchanfrage zu berechnen und die Ergebnisse entsprechend zu ranken.
Anmerkungen
Wie oben in der IDF Ausgabe zu sehen ist, achtet der Algorithmus in der einfachen Implementierung nicht auf Groß- oder Kleinschreibung. „Ich“ und „ich“ werden als zwei unterschiedliche Vektoren gespeichert. Ich hatte auch zuerst in der Dokumentensammlung hinter jedem Satz einen Punkt, in der Suchanfrage aber den Punkt hinter „Pizza“ weggelassen, sodass die Metrik ausgegeben hat, dass „Pizza“ ohne Punkt nicht in der Dokumentensammlung enthalten ist.